Wenn wir Tools wie Skype und QQ verwenden, um reibungslos Sprach- und Video-Chats mit Freunden zu führen, haben wir uns dann jemals gefragt, welche leistungsstarken Technologien dahinterstecken? Dieser Artikel gibt eine kurze Einführung in die Technologien, die bei Netzwerk-Sprachanrufen verwendet werden, was als ein Vorgeschmack auf den Leoparden angesehen werden kann.
1. Konzeptionelles Modell
Internet-Sprachanrufe erfolgen normalerweise in beide Richtungen, was auf Modellebene symmetrisch ist. Der Einfachheit halber können wir den Kanal in eine Richtung diskutieren. Ein Teilnehmer spricht und der andere Teilnehmer hört die Stimme. Es scheint einfach und schnell, aber der Prozess dahinter ist ziemlich kompliziert.
Dies ist das grundlegendste Modell, das aus fünf wichtigen Verknüpfungen besteht: Erfassung, Kodierung, Übertragung, Dekodierung und Wiedergabe.
(1) Sprachsammlung
Unter Sprachsammlung versteht man das Sammeln von Audiodaten von einem Mikrofon, also die Umwandlung von Klangproben in digitale Signale. Sie umfasst mehrere wichtige Parameter: Abtastfrequenz, Anzahl der Abtastbits und Anzahl der Kanäle.
Einfach ausgedrückt: Die Abtastfrequenz ist die Anzahl der Erfassungsaktionen in 1 Sekunde; Die Anzahl der Abtastbits ist die Länge der Daten, die für jede Erfassungsaktion erhalten werden.
Die Größe eines Audioframes ist gleich: (Abtastfrequenz × Anzahl der Abtastbits × Anzahl der Kanäle × Zeit)
Normalerweise beträgt die Dauer eines Abtastrahmens 10 ms, dh alle 10 ms Daten bilden einen Audiorahmen. Angenommen: die Abtastrate beträgt 16k, die Anzahl der Abtastbits beträgt 16bit und die Anzahl der Kanäle ist 1, dann ist die Größe eines 10ms Audioframes: (16000*16*1*0.01)/8 = 320 Bytes. In der Berechnungsformel ist 0.01 eine Sekunde, also 10 ms.
(2) Kodierung
Angenommen, wir senden den gesammelten Audio-Frame direkt ohne Kodierung, dann können wir den erforderlichen Bandbreitenbedarf berechnen. Noch das obige Beispiel: 320*100 = 32KBytes/s, umgerechnet in Bits/s sind es 256kb/s. Dies ist eine Menge Bandbreitennutzung. Mit Tools zur Überwachung des Netzwerkverkehrs können wir feststellen, dass bei Sprachanrufen mit IM-Software wie QQ der Datenverkehr 3-5 KB/s beträgt, was eine Größenordnung kleiner ist als der ursprüngliche Datenverkehr. Dies ist hauptsächlich auf die Audiocodierungstechnologie zurückzuführen. Daher ist diese Kodierungsverbindung in der tatsächlichen Sprachanrufanwendung unverzichtbar. Es gibt viele häufig verwendete Sprachcodierungstechnologien wie G.729, iLBC, AAC, SPEEX usw.
(3) Netzwerkübertragung
Wenn ein Audioframe codiert ist, kann es über das Netzwerk an den Anrufer gesendet werden. Für Echtzeitanwendungen wie Sprachgespräche sind geringe Latenz und Stabilität sehr wichtig, was eine sehr reibungslose Übertragung unseres Netzwerks erfordert.
(4) Dekodierung
Wenn der andere Teilnehmer den codierten Frame empfängt, wird er ihn decodieren, um ihn in Daten wiederherzustellen, die direkt von der Soundkarte abgespielt werden können.
(5) Sprachwiedergabe
Nachdem die Dekodierung abgeschlossen ist, kann der erhaltene Audiorahmen zur Wiedergabe an die Soundkarte gesendet werden. Anhang: Sie können sich auf die Einführung und den Demo-Quellcode und den SDK-Download von MPlayer, einer Sprachwiedergabekomponente, beziehen
2. Schwierigkeiten und Lösungen in der praktischen Anwendung
Wenn man sich nur auf die oben erwähnte Technologie verlassen kann, um ein auf das Weitverkehrsnetz angewendetes Klangdialogsystem zu realisieren, dann ist es nicht notwendig, diesen Artikel zu schreiben. Gerade viele realistische Faktoren haben viele Herausforderungen für das oben erwähnte konzeptionelle Modell mit sich gebracht, was die Realisierung des Netzwerk-Sprachsystems, das viele professionelle Technologien beinhaltet, nicht so einfach macht. Natürlich gibt es für die meisten dieser Herausforderungen bereits ausgereifte Lösungen. Zunächst müssen wir ein Sprachdialogsystem mit "guter Wirkung" definieren. Ich denke, es sollte folgende Punkte erreichen:
(1) Niedrige Latenz. Nur bei geringer Latenz können die beiden Gesprächspartner ein starkes Echtzeitgefühl haben. Dies hängt natürlich hauptsächlich von der Geschwindigkeit des Netzwerks und der Entfernung zwischen den physischen Standorten der beiden Gesprächsteilnehmer ab. Aus Sicht der reinen Software ist die Optimierungsmöglichkeit sehr gering.
(2) Geringe Hintergrundgeräusche.
(3) Der Klang ist weich, ohne das Gefühl, stecken zu bleiben oder anzuhalten.
(4) Es erfolgt keine Antwort.
Im Folgenden werden wir nacheinander über die zusätzlichen Technologien sprechen, die im eigentlichen Netzwerk-Sprachdialogsystem verwendet werden.
1. Echounterdrückung AEC Fast jeder ist es mittlerweile gewohnt, während des Voice-Chats direkt die Sprachwiedergabefunktion des PCs oder Notebooks zu verwenden. Wie jeder weiß, hat diese kleine Angewohnheit die Sprachtechnologie vor eine große Herausforderung gestellt. Bei Verwendung der Lautsprecherfunktion wird der vom Lautsprecher abgespielte Ton vom Mikrofon wieder aufgenommen und an den Gesprächspartner zurückgesendet, sodass der Gesprächspartner sein eigenes Echo hören kann. Daher ist in praktischen Anwendungen die Funktion der Echokompensation notwendig. Nachdem der gesammelte Audiorahmen erhalten wurde, ist diese Lücke vor der Codierung die Zeit, in der das Echokompensationsmodul arbeitet. Das Prinzip besteht einfach darin, dass das Echokompensationsmodul einige löschungsähnliche Operationen in dem gesammelten Audiorahmen entsprechend dem gerade abgespielten Audiorahmen durchführt, um das Echo aus dem gesammelten Rahmen zu entfernen. Dieser Vorgang ist ziemlich kompliziert und hängt auch von der Größe des Raums ab, in dem Sie sich beim Chatten befinden, und Ihrer Position im Raum, da diese Informationen die Länge der Schallwellenreflexion bestimmen. Das intelligente Echokompensationsmodul kann die internen Parameter dynamisch anpassen, um sich optimal an die aktuelle Umgebung anzupassen.
2. Rauschunterdrückung DENOISE Rauschunterdrückung, auch als Rauschunterdrückung bekannt, basiert auf den Eigenschaften von Sprachdaten, um den Teil des Hintergrundrauschens zu erkennen und aus Audioframes herauszufiltern. Viele Encoder haben diese Funktion eingebaut.
3. JitterBuffer Der Jitterbuffer wird verwendet, um das Problem des Netzwerkjitters zu lösen. Der sogenannte Netzwerkjitter bedeutet, dass die Netzwerkverzögerung größer und kleiner wird. Selbst wenn der Sender regelmäßig Datenpakete sendet (beispielsweise wird alle 100 ms ein Paket gesendet), kann der Empfänger in diesem Fall nicht das gleiche Timing empfangen. Manchmal kann kein Paket in einem Zyklus empfangen werden, und manchmal werden mehrere Pakete in einem Zyklus empfangen. Auf diese Weise ist der Ton, den der Empfänger hört, eine Karte, eine Karte. JitterBuffer arbeitet nach dem Decoder und vor der Sprachwiedergabe. Das heißt, nachdem die Sprachdecodierung abgeschlossen ist, wird der decodierte Frame in den JitterBuffer gestellt, und wenn der Playback-Callback der Soundkarte eintrifft, wird der älteste Frame aus dem JitterBuffer zur Wiedergabe abgerufen. Die Puffertiefe von JitterBuffer hängt vom Grad des Netzwerkjitters ab. Je größer der Netzwerk-Jitter, desto größer die Puffertiefe und desto größer die Verzögerung bei der Audiowiedergabe. Daher verwendet JitterBuffer eine höhere Verzögerung im Austausch für eine reibungslose Soundwiedergabe, da im Vergleich zum Sound einer Karte eine Karte eine etwas größere Verzögerung, aber eine glattere Wirkung hat, seine subjektive Erfahrung ist besser. Natürlich ist die Puffertiefe von JitterBuffer nicht konstant, sondern wird dynamisch an Änderungen des Netzwerk-Jitter-Grades angepasst. Wenn das Netzwerk wieder sehr glatt und ungehindert ist, ist die Puffertiefe sehr gering, so dass die Zunahme der Wiedergabeverzögerung aufgrund von JitterBuffer vernachlässigbar ist.
4. Stummschaltungserkennung VAD Wenn in einem Sprachgespräch ein Teilnehmer nicht spricht, wird kein Verkehr generiert. Dazu wird die Mute-Erkennung verwendet. Die Mute-Erkennung ist in der Regel auch im Kodiermodul integriert. Der Algorithmus zur stillen Erkennung in Kombination mit dem vorherigen Algorithmus zur Geräuschunterdrückung kann erkennen, ob derzeit eine Spracheingabe erfolgt. Wenn keine Spracheingabe erfolgt, kann es einen speziell codierten Frame codieren und ausgeben (z. B. die Länge ist 0). Gerade bei einer Mehrpersonen-Videokonferenz spricht meist nur eine Person. In diesem Fall ist der Einsatz von Silent-Detection-Technologie zur Einsparung von Bandbreite noch sehr beachtlich.
5. Mischalgorithmus In einem Sprachchat mit mehreren Personen müssen wir die Sprachdaten mehrerer Personen gleichzeitig abspielen, und die Soundkarte spielt nur einen Puffer ab. Daher müssen wir mehrere Stimmen zu einer mischen. Das macht der Mischalgorithmus. Selbst wenn Sie einen Weg finden können, das Mischen zu umgehen und mehrere Sounds gleichzeitig abspielen zu lassen, muss diese zum Zweck der Echounterdrückung in eine Wiedergabe gemischt werden, andernfalls kann die Echounterdrückung nur einige der mehreren Töne bei eliminate die meisten. Den ganzen Weg. Das Mischen kann auf der Clientseite oder auf der Serverseite erfolgen (was Downstream-Bandbreite sparen kann). Wenn P2P-Kanäle verwendet werden, kann das Mischen nur auf der Client-Seite erfolgen. Wenn es auf dem Client mischt, ist das Mischen normalerweise der letzte Link vor dem Abspielen. Dieser Artikel ist eine grobe Zusammenfassung unserer Erfahrungen bei der Implementierung des Voice-Teils von OMCS. Hier haben wir nur eine einfache Beschreibung jedes Links in der Abbildung gemacht, und jeder von ihnen kann in ein langes Papier oder sogar in ein Buch geschrieben werden. Daher soll dieser Artikel nur eine einführende Karte für diejenigen bieten, die neu in der Entwicklung von Netzwerk-Sprachsystemen sind, und einige Hinweise geben.



|
|
|
|
Wie weit (lang) der Sender ab?
Die Reichweite hängt von vielen Faktoren ab. Der wahre Abstand basiert auf der Installation der Antenne Höhe, Antennengewinn, Umgebung mit wie Gebäude und andere Hindernisse, Empfindlichkeit des Empfängers, Antenne des Empfängers. Installieren Antenne mehr hoch, und unter Verwendung von auf dem Land, der Abstand wird viel mehr weit.
Beispiel 5W FM-Transmitter verwenden in der Stadt und Heimatstadt:
Ich habe einen USA-Kunden Gebrauch 5W FM-Transmitter mit GP-Antenne in seiner Heimatstadt, und er es mit einem Auto zu testen, es decken 10km (6.21mile).
Ich teste die 5W FM-Transmitter mit GP-Antenne in meiner Heimatstadt, sie decken etwa 2km (1.24mile).
Ich teste die 5W FM-Transmitter mit GP-Antenne in der Stadt Guangzhou, decken sie etwa nur 300meter (984ft).
Im Folgenden sind die ungefähren Bereich unterschiedlicher Leistung FM-Transmitter. (Der Bereich ist Durchmesser)
0.1W ~ 5W FM-Transmitter: 100M ~ 1KM
5W ~ 15W FM Ttransmitter: 1KM ~ 3KM
15W ~ 80W FM-Transmitter: 3KM ~ 10KM
80W ~ 500W FM-Transmitter: 10KM ~ 30KM
500W ~ 1000W FM-Transmitter: 30KM ~ 50KM
1KW ~ 2KW FM-Transmitter: 50KM ~ 100KM
2KW ~ 5KW FM-Transmitter: 100KM ~ 150KM
5KW ~ 10KW FM-Transmitter: 150KM ~ 200KM
Wie uns für den Sender zu kontaktieren?
Rufen Sie mich an + 8618078869184 ODER
Maile mir [E-Mail geschützt]
1.How weit wollen Sie im Durchmesser zu decken?
2.How hohen Turm von euch?
3.Where sind Sie?
Und wir werden Ihnen mehr professionelle Beratung geben.
Über uns
FMUSER.ORG ist ein Systemintegrationsunternehmen, das sich auf die drahtlose HF-Übertragung / Studio-Video-Audio-Ausrüstung / Streaming und Datenverarbeitung konzentriert. Wir bieten alles von Beratung über Rack-Integration bis hin zu Installation, Inbetriebnahme und Schulung.
Wir bieten FM-Sender, Analog-TV-Sender, Digital-TV-Sender, UKW-UHF-Sender, Antennen, Koaxialkabel-Steckverbinder, STL, On-Air-Verarbeitung, Rundfunkprodukte für das Studio, RF-Signalüberwachung, RDS-Encoder, Audioprozessoren und Remote Site Control Units, IPTV-Produkte, Video / Audio-Encoder / -Decoder, wurden entwickelt, um die Anforderungen sowohl großer internationaler Rundfunknetze als auch kleiner privater Sender zu erfüllen.
Unsere Lösung verfügt über FM-Radiosender / Analog-TV-Sender / Digital-TV-Sender / Audio-Video-Studio-Ausrüstung / Studio-Senderverbindung / Sender-Telemetriesystem / Hotel-TV-System / IPTV-Live-Übertragung / Streaming-Live-Übertragung / Videokonferenz / CATV-Übertragungssystem.
Wir verwenden fortschrittliche Technologieprodukte für alle Systeme, da wir wissen, dass hohe Zuverlässigkeit und hohe Leistung für das System und die Lösung so wichtig sind. Gleichzeitig müssen wir auch sicherstellen, dass unser Produktsystem zu einem sehr vernünftigen Preis angeboten wird.
Wir haben Kunden von öffentlich-rechtlichen und kommerziellen Rundfunkanstalten, Telekommunikationsbetreibern und Regulierungsbehörden und bieten Lösungen und Produkte auch vielen Hunderten kleinerer, lokaler und kommunaler Rundfunkanstalten an.
FMUSER.ORG exportiert seit mehr als 15 Jahren und hat Kunden auf der ganzen Welt. Mit 13 Jahren Erfahrung auf diesem Gebiet verfügen wir über ein professionelles Team, um alle Arten von Kundenproblemen zu lösen. Wir sind bestrebt, die äußerst günstigen Preise für professionelle Produkte und Dienstleistungen zu liefern. Kontakt E-mail : [E-Mail geschützt]
UNSER WERK

Wir haben Modernisierung der Fabrik. Sie sind willkommen, unsere Fabrik zu besuchen, wenn Sie nach China kommen.

Derzeit gibt es bereits 1095 Kunden auf der ganzen Welt besuchte unser Büro Guangzhou Tianhe. Wenn Sie nach China kommen, sind Sie herzlich eingeladen, uns zu besuchen.
Am Messe

Dies ist unsere Teilnahme an 2012 Global Sources Hong Kong Electronics Fair . Kunden aus der ganzen Welt schließlich haben eine Chance, zusammen zu bekommen.
Wo ist FMUSER?
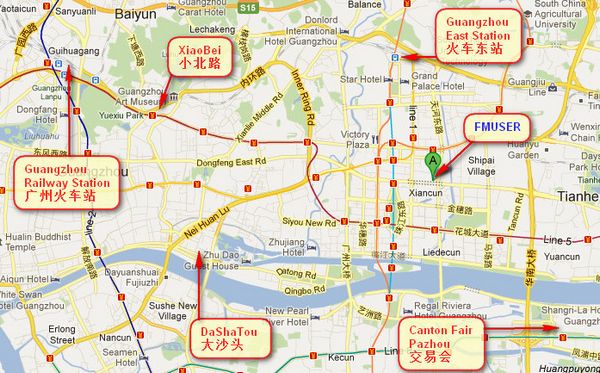
Sie können diese Nummern suchen " 23.127460034623816,113.33224654197693 "in google map finden sie dann unser fmuser büro.
FMUSER Guangzhou Büro befindet sich in Tianhe District, welche das ist Zentrum des Kantons . Sehr in der Nähe von zu den Canton Fair , guangzhou Bahnhof, Xiaobei Straße und Dashatou , brauche nur 10 Мinuten wenn übernehmen TAXI . Willkommen Freunde auf der ganzen Welt zu besuchen und zu verhandeln.
Kontakt: Sky Blue
Telefon: + 8618078869184
WhatsApp: +8618078869184
WeChat: + 8618078869184
E-Mail: [E-Mail geschützt]
QQ: 727926717
Skype: sky198710021
Adresse: No.305 Zimmer Huilan Gebäude No.273 Huanpu Straße Guangzhou China PLZ: 510620
|
|
|
|
Englisch: Wir akzeptieren alle Zahlungen wie PayPal, Kreditkarte, Western Union, Alipay, Geldbucher, T / T, LC, DP, DA, OA, Payoneer. Wenn Sie Fragen haben, kontaktieren Sie mich bitte [E-Mail geschützt] oder WhatsApp + 8618078869184
-
PayPal.  www.paypal.com www.paypal.com
Wir empfehlen Ihnen, Paypal benutzen unsere Produkte zu kaufen, die Paypal ist eine sichere Möglichkeit, im Internet zu kaufen.
Jedes unserer Artikelliste Seite unten auf ein PayPal-Logo zu bezahlen.
Kreditkarte.Wenn Sie nicht paypal haben, aber Sie Kreditkarte haben, können Sie auch den Yellow PayPal-Button klicken Sie mit Ihrer Kreditkarte zu bezahlen.
-------------------------------------------------- -------------------
Aber wenn Sie nicht über eine Kreditkarte und haben kein PayPal-Konto oder schwierig, eine paypal accout zu bekommen, können Sie verwenden, um die folgenden:
Western Union.  www.westernunion.com www.westernunion.com
Bezahlen per Western Union zu mir:
Vorname / Vorname: Yingfeng
Nachname / Nachname / Nachname: Zhang
Voller Name: Yingfeng Zhang
Land: China
Ort: Guangzhou
|
-------------------------------------------------- -------------------
T / T. Zahlung per T / T (Überweisung / Telegraphen Transfer / Banküberweisung)
Erste BANKINFORMATION (UNTERNEHMENSKONTO):
SWIFT BIC: BKCHHKHHXXX
Bankname: BANK VON CHINA (HONG KONG) LIMITED, HONGKONG
Bankadresse: BANK DES CHINA-TURMES, 1-GARTEN-STRASSE, ZENTRAL, HONGKONG
BANK-CODE: 012
Kontoname: FMUSER INTERNATIONAL GROUP LIMITED
Konto Nr. : 012-676-2-007855-0
-------------------------------------------------- -------------------
Zweite BANKDATEN (UNTERNEHMENSKONTO):
Begünstigter: Fmuser International Group Inc
Kontonummer: 44050158090900000337
Bank des Begünstigten: China Construction Bank Filiale Guangdong
SWIFT-Code: PCBCCNBJGDX
Adresse: NO.553 Tianhe Road, Guangzhou, Guangdong, Tianhe-Bezirk, China
**Hinweis: Wenn Sie Geld auf unser Bankkonto überweisen, schreiben Sie bitte nichts in das Bemerkungsfeld, da wir sonst die Zahlung aufgrund der Regierungspolitik zum internationalen Handelsgeschäft nicht erhalten können.
|
|
|
|
* Es wird in 1-2 geschickt Tage zu arbeiten, wenn die Zahlung klar.
* Wir werden es zu Ihrer paypal Adresse. Wenn Sie Adresse ändern möchten, benutzen Sie bitte Ihre korrekte Adresse und Telefonnummer per E-Mail senden [E-Mail geschützt]
* Wenn die Pakete unter 2kg ist, werden wir per Post Luftpost verschickt werden, wird es über 15-25days auf die Hand nehmen.
Wenn das Paket mehr als 2kg ist, werden wir über EMS, DHL, UPS, Fedex schnell Expressversand versendet, dauert es etwa 7 nehmen ~ 15days auf die Hand.
Wenn das Paket mehr als 100kg, werden wir über DHL oder Luftfracht schicken. Es wird etwa 3 nehmen ~ 7days auf die Hand.
Alle Pakete sind Form China Guangzhou.
* Das Paket wird als "Geschenk" verschickt und so wenig wie möglich deklariert. Der Käufer muss nicht für "STEUER" bezahlen.
* Nach dem Schiff, werden wir Ihnen eine E-Mail und geben Sie die Tracking-Nummer senden.
|
|
|
Für die Garantie.
Kontaktieren Sie uns --- >> Senden Sie den Artikel an uns zurück --- >> Empfangen und senden Sie einen weiteren Ersatz.
Name: Liu Xiaoxia
Adresse: 305Fang HuiLanGe HuangPuDaDaoXi 273Hao TianHeQu Guangzhou China.
PLZ: 510620
Telefon: +8618078869184 (XNUMX)XNUMX XNUMX XNUMX XNUMX
Bitte kehren Sie zu dieser Adresse und schreiben Sie Ihre PayPal-Adresse, Name, Problem auf Hinweis: |
|













