(1) Redundante Information des Videosignals
Am Beispiel des YUV-Komponentenformats für die Aufzeichnung digitaler Videos repräsentiert YUV die Helligkeit bzw. zwei Farbdifferenzsignale. Beispielsweise beträgt für ein vorhandenes Pal-TV-System die Abtastfrequenz des Luminanzsignals 13.5 MHz; Das Frequenzband des Chroma-Signals beträgt normalerweise die Hälfte oder weniger des Helligkeitssignals, das 6.75 MHz oder 3.375 MHz beträgt. Am Beispiel der Abtastfrequenz von 4: 2: 2 nimmt das Y-Signal 13.5 MHz an, das Chroma-Signal U und V werden mit 6.75 MHz abgetastet, und das Abtastsignal wird mit 8 Bit quantisiert, und dann kann die Coderate des digitalen Videos berechnet werden wie folgt:
13.5 * 8 + 6.75 * 8 + 6.75 * 8 = 216 Mbit / s
Wenn eine so große Datenmenge direkt gespeichert oder übertragen wird, ist es schwierig, die Komprimierungstechnologie zu verwenden, um die Bitrate zu verringern. Das digitale Videosignal kann unter zwei Grundbedingungen komprimiert werden:
L. Datenredundanz. Zum Beispiel räumliche Redundanz, Zeitredundanz, Strukturredundanz, Informationsentropie-Redundanz usw., dh es besteht eine starke Korrelation zwischen Pixeln des Bildes. Das Eliminieren dieser Redundanz führt nicht zu Informationsverlust und ist zu einer verlustfreien Komprimierung.
L. visuelle Redundanz. Einige Merkmale des menschlichen Auges, wie die Helligkeitsunterscheidungsschwelle und die visuelle Schwelle, unterscheiden sich in der Empfindlichkeit gegenüber Helligkeit und Chroma, was es unmöglich macht, geeignete Codierungsfehler einzuführen, und werden nicht erkannt. Die visuellen Eigenschaften des menschlichen Auges können verwendet werden, um Datenkomprimierung mit bestimmten objektiven Verzerrungen auszutauschen. Diese Komprimierung ist verlustbehaftet.
Die Komprimierung des digitalen Videosignals basiert auf den beiden oben genannten Bedingungen, wodurch die Videodaten stark komprimiert werden, was der Übertragung und Speicherung förderlich ist. Die üblichen Methoden der digitalen Videokomprimierung sind gemischte Codierungen, bei denen Transformationscodierung, Bewegungsschätzung und Bewegungskompensation sowie Entropiecodierung kombiniert werden, um die Codierung zu komprimieren. Normalerweise wird eine Transformationscodierung verwendet, um die Intra-Frame-Redundanz des Bildes zu beseitigen, und eine Bewegungsschätzung und eine Bewegungskompensation werden verwendet, um die Interframe-Redundanz des Bildes zu beseitigen, und eine Entropiecodierung wird verwendet, um die Komprimierungseffizienz weiter zu verbessern. Die folgenden drei Komprimierungscodierungsmethoden werden kurz vorgestellt.
(a) Kompressionscodierungsverfahren
(b) Transformationscodierung
Die Funktion der Transformationscodierung besteht darin, das im Raumbereich beschriebene Bildsignal in den Frequenzbereich umzuwandeln und dann die transformierten Koeffizienten zu codieren. Im Allgemeinen weist das Bild eine starke Korrelation im Raum auf, und die Transformation in den Frequenzbereich kann eine Dekorrelation und Energiekonzentration realisieren. Die gemeinsame orthogonale Transformation umfasst eine diskrete Fourier-Transformation, eine diskrete Cosinustransformation und so weiter. Die diskrete Cosinustransformation wird häufig bei der digitalen Videokomprimierung verwendet.
Die diskrete Cosinustransformation wird als DCT-Transformation bezeichnet. Es kann den Bildblock von L * l von der Raumdomäne in die Frequenzdomäne transformieren. Daher muss bei der Bildkomprimierung und -codierung auf der Basis von DCT das Bild in nicht überlappende Bildblöcke unterteilt werden. Angenommen, die Größe eines Bildes beträgt 1280 * 720, es ist in 160 * 90 Bildblöcke mit einer Größe von 8 * 8 unterteilt, ohne sich in Form eines Rasters zu überlappen. Dann kann für jeden Bildblock eine DCT-Transformation durchgeführt werden.
Nachdem der Block geteilt wurde, wird jeder 8 * 8-Punkt-Bildblock an den DCT-Codierer gesendet, und der 8 * 8-Bildblock wird vom räumlichen Bereich in den Frequenzbereich transformiert. Die folgende Abbildung zeigt ein Beispiel eines Bildblocks von 8 * 8, in dem die Zahl den Helligkeitswert jedes Pixels darstellt. Aus der Figur ist ersichtlich, dass die Helligkeitswerte jedes Pixels in diesem Bildblock relativ gleichmäßig sind, insbesondere ist der Helligkeitswert benachbarter Pixel nicht sehr groß, was anzeigt, dass das Bildsignal eine starke Korrelation aufweist.
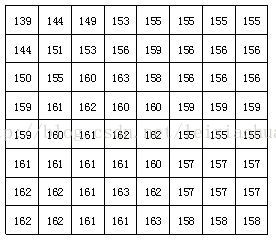
Ein tatsächlicher 8 * 8-Bildblock
Die folgende Abbildung zeigt die Ergebnisse der DCT-Transformation des Bildblocks in der obigen Abbildung. Aus der Abbildung ist ersichtlich, dass nach der DCT-Transformation der Niederfrequenzkoeffizient in der oberen linken Ecke viel Energie konzentriert, während die Energie auf dem Hochfrequenzkoeffizienten in der unteren rechten Ecke sehr klein ist.
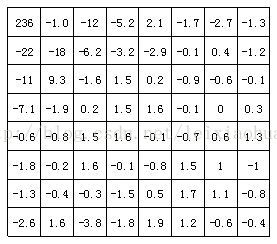
Die Koeffizienten des Bildblocks nach der DCT-Transformation
Das Signal muss nach der DCT-Transformation quantifiziert werden. Da menschliche Augen empfindlich auf niederfrequente Eigenschaften von Bildern wie die Gesamthelligkeit von Objekten und nicht auf hochfrequente Details im Bild reagieren, können hochfrequente Informationen während des Übertragungsprozesses nur weniger oder nicht übertragen werden der niederfrequente Teil. Der Quantisierungsprozess reduziert die Informationsübertragung durch Quantifizierung der Koeffizienten des Niederfrequenzbereichs und durch Grobquantisierung der Koeffizienten im Hochfrequenzbereich, wodurch die für das menschliche Auge nicht empfindlichen Hochfrequenzinformationen entfernt werden. Daher ist die Quantisierung ein verlustbehafteter Komprimierungsprozess und der Hauptgrund für den Qualitätsschaden bei der Videokomprimierungscodierung.
Der Quantifizierungsprozess kann durch die folgende Formel ausgedrückt werden:

Unter diesen repräsentiert FQ (U, V) den DCT-Koeffizienten nach der Quantisierung; f (U, V) stellt den DCT-Koeffizienten vor der Quantisierung dar; Q (U, V) stellt eine Quantisierungsgewichtungsmatrix dar; q ist der Quantisierungsschritt; Die Runde bezieht sich auf die Konsolidierung, und der auszugebende Wert wird als nächster ganzzahliger Wert verwendet.
Wählen Sie den Quantisierungskoeffizienten angemessen aus, und das Ergebnis nach der Quantisierung des transformierten Bildblocks ist in der Abbildung dargestellt.

DCT-Koeffizient nach Quantifizierung
Die meisten DCT-Koeffizienten werden nach der Quantisierung auf 0 geändert, während nur wenige Koeffizienten Werte ungleich Null sind. Zu diesem Zeitpunkt müssen nur diese Werte ungleich Null komprimiert und codiert werden.
(b) Entropiecodierung
Die Entropiecodierung wird benannt, weil die durchschnittliche Codelänge nach der Codierung nahe am Entropiewert der Quelle liegt. Die Entropiecodierung wird durch VLC (Codierung mit variabler Länge) implementiert. Das Grundprinzip besteht darin, dem Symbol mit hoher Wahrscheinlichkeit in der Quelle Kurzcode und dem Symbol mit geringer Wahrscheinlichkeit des Auftretens langen Code zu geben, um statistisch die kürzere durchschnittliche Codelänge zu erhalten. Die Codierung mit variabler Länge umfasst normalerweise Hoffman-Code, arithmetischen Code, Ausführungscode usw. Die Lauflängencodierung ist eine sehr einfache Komprimierungsmethode, ihre Komprimierungseffizienz ist nicht hoch, aber die Codierungs- und Decodierungsgeschwindigkeit ist schnell und wird insbesondere immer noch häufig verwendet Nach der Transformation der Codierung hat die Verwendung der Lauflängencodierung einen guten Effekt.
Zunächst ist der Wechselstromkoeffizient unmittelbar nach dem Ausgangs-Gleichstromkoeffizienten des Quantisierers vom Z-Typ abzutasten (wie in der Pfeillinie gezeigt). Der Z-Scan transformiert den zweidimensionalen Quantisierungskoeffizienten in eine eindimensionale Sequenz und setzt dann die Lauflängencodierung fort. Schließlich wird ein anderer Code variabler Länge verwendet, um die Daten nach der Laufcodierung zu codieren, wie beispielsweise die Hoffman-Codierung. Durch diese Art der Codierung mit variabler Länge wird die Effizienz der Codierung weiter verbessert.
(c) Bewegungsschätzung und Bewegungskompensation
Bewegungsschätzung und Bewegungskompensation sind wirksame Methoden, um die Korrelation der Zeitrichtung von Bildsequenzen zu beseitigen. Die oben beschriebenen DCT-Transformations-, Quantisierungs- und Entropiecodierungsverfahren basieren auf einem Einzelbild. Durch diese Verfahren kann die räumliche Korrelation zwischen Pixeln im Bild beseitigt werden. Zusätzlich zur räumlichen Korrelation weist das Bildsignal eine zeitliche Korrelation auf. Beispielsweise ist bei digitalen Videos mit statischem Hintergrund wie Nachrichtenübertragungen und kleinen Bewegungen des Hauptbildkörpers der Unterschied zwischen den einzelnen Bildern sehr gering und die Korrelation zwischen den Bildern sehr groß. In diesem Fall müssen wir nicht jedes Einzelbild einzeln codieren, sondern können nur die geänderten Teile benachbarter Videobilder codieren, um die Datenmenge weiter zu reduzieren. Diese Arbeit wird durch Bewegungsschätzung und Bewegungskompensation realisiert.
Die Bewegungsschätzungstechnologie unterteilt das aktuelle Eingabebild im Allgemeinen in mehrere kleine Bildunterblöcke, die sich nicht überlappen. Beispielsweise beträgt die Größe eines Rahmenbilds 1280 * 720. Erstens wird es in 40 * 45 Bildblöcke mit 16 * unterteilt. 16 Größe, die sich nicht in Form eines Gitters überlappen, und dann im Rahmen eines Suchfensters des vorherigen Bildes oder des letzteren Bildes einen Block für jeden Bildblock finden, um einen Bildblock im Rahmen von a zu finden Suchfenster Der ähnlichste Bildblock. Der Suchvorgang wird als Bewegungsschätzung bezeichnet. Durch Berechnen der Positionsinformationen zwischen dem ähnlichsten Bildblock und dem Bildblock kann ein Bewegungsvektor erhalten werden. Auf diese Weise kann der aktuelle Bildblock von dem ähnlichsten Bildblock subtrahiert werden, auf den der Referenzbildbewegungsvektor zeigt, und es kann ein Restbildblock erhalten werden. Da jeder Pixelwert im Restbildblock sehr klein ist, kann bei der Komprimierungscodierung ein höheres Komprimierungsverhältnis erhalten werden. Dieser Subtraktionsprozess wird als Bewegungskompensation bezeichnet.
Da das Referenzbild für die Bewegungsschätzung und Bewegungskompensation im Codierungsprozess verwendet werden muss, ist es sehr wichtig, das Referenzbild auszuwählen. Im Allgemeinen unterteilt der Codierer jeden eingegebenen Rahmenbild in drei verschiedene Typen gemäß den verschiedenen Referenzbildern: I-Rahmen (Intra-Rahmen), B-Rahmen (Führungsvorhersage) und P-Rahmen (Vorhersage-Rahmen). Wie in der Abbildung gezeigt.
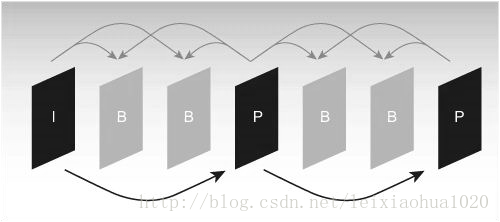
Typische I-, B-, P-Rahmenstruktursequenz
Wie in der Abbildung gezeigt, verwendet der I-Frame nur die Daten im Frame zum Codieren und benötigt während des Codierungsprozesses keine Bewegungsschätzung und Bewegungskompensation. Da der I-Frame die Korrelation der Zeitrichtung nicht beseitigt, ist das Kompressionsverhältnis offensichtlich relativ niedrig. Während des Codierungsprozesses verwendet der P-Rahmen einen vorderen I-Rahmen oder einen P-Rahmen als Referenzbild für die Bewegungskompensation. Tatsächlich codiert er die Differenz zwischen dem aktuellen Bild und dem Referenzbild. Der Codierungsmodus des B-Rahmens ist dem P-Rahmen ähnlich. Der einzige Unterschied besteht darin, dass ein vorderer I-Rahmen oder P-Rahmen und ein späterer I-Rahmen oder P-Rahmen verwendet werden müssen, um während des Codierungsprozesses vorherzusagen. Somit muss jede P-Rahmencodierung ein Rahmenbild als Referenzbild verwenden, während Rahmen B zwei Rahmen als Referenz benötigt. Im Gegensatz dazu hat der B-Rahmen ein höheres Komprimierungsverhältnis als der P-Rahmen.
(d) Gemischte Codierung
In diesem Artikel werden verschiedene wichtige Methoden zur Videokomprimierung und -codierung vorgestellt. In der praktischen Anwendung werden diese Methoden nicht getrennt und normalerweise kombiniert, um den besten Kompressionseffekt zu erzielen. Die folgende Abbildung zeigt das Modell der Hybridcodierung (dh Transformationscodierung + Bewegungsschätzung und Bewegungskompensation + Entropiecodierung). Das Modell ist in MPEG1, MPEG2, H.264 und anderen Standards weit verbreitet. Aus der Abbildung ist ersichtlich, dass das aktuelle Eingabebild zuerst in Blöcke unterteilt werden muss. Der vom Block erhaltene Block des Bildes wird von der abgezogen vorhergesagtes Bild nach Bewegungskompensation, um das Differenzbild x zu erhalten, und dann DCT-Transformation und Quantisierung werden für den Differenzbildblock durchgeführt. Die quantisierten Ausgabedaten haben zwei verschiedene Stellen: Eine besteht darin, sie zur Codierung an den Entropiecodierer zu senden, und der codierte Codestream wird in einen Cache ausgegeben. Speichern Sie im Gerät und warten Sie auf die Übertragung. Eine andere Anwendung besteht darin, der Quantifizierung und Umkehrung der Änderung des Signals x 'entgegenzuwirken, wodurch die Bildblockausgabe mit Bewegungskompensation addiert wird, um ein neues Vorhersagebildsignal zu erhalten, und ein neuer Vorhersagebildblock an den Rahmenspeicher gesendet wird.



|
|
|
|
Wie weit (lang) der Sender ab?
Die Reichweite hängt von vielen Faktoren ab. Der wahre Abstand basiert auf der Installation der Antenne Höhe, Antennengewinn, Umgebung mit wie Gebäude und andere Hindernisse, Empfindlichkeit des Empfängers, Antenne des Empfängers. Installieren Antenne mehr hoch, und unter Verwendung von auf dem Land, der Abstand wird viel mehr weit.
Beispiel 5W FM-Transmitter verwenden in der Stadt und Heimatstadt:
Ich habe einen USA-Kunden Gebrauch 5W FM-Transmitter mit GP-Antenne in seiner Heimatstadt, und er es mit einem Auto zu testen, es decken 10km (6.21mile).
Ich teste die 5W FM-Transmitter mit GP-Antenne in meiner Heimatstadt, sie decken etwa 2km (1.24mile).
Ich teste die 5W FM-Transmitter mit GP-Antenne in der Stadt Guangzhou, decken sie etwa nur 300meter (984ft).
Im Folgenden sind die ungefähren Bereich unterschiedlicher Leistung FM-Transmitter. (Der Bereich ist Durchmesser)
0.1W ~ 5W FM-Transmitter: 100M ~ 1KM
5W ~ 15W FM Ttransmitter: 1KM ~ 3KM
15W ~ 80W FM-Transmitter: 3KM ~ 10KM
80W ~ 500W FM-Transmitter: 10KM ~ 30KM
500W ~ 1000W FM-Transmitter: 30KM ~ 50KM
1KW ~ 2KW FM-Transmitter: 50KM ~ 100KM
2KW ~ 5KW FM-Transmitter: 100KM ~ 150KM
5KW ~ 10KW FM-Transmitter: 150KM ~ 200KM
Wie uns für den Sender zu kontaktieren?
Rufen Sie mich an + 8618078869184 ODER
Maile mir [E-Mail geschützt]
1.How weit wollen Sie im Durchmesser zu decken?
2.How hohen Turm von euch?
3.Where sind Sie?
Und wir werden Ihnen mehr professionelle Beratung geben.
Über uns
FMUSER.ORG ist ein Systemintegrationsunternehmen, das sich auf die drahtlose HF-Übertragung / Studio-Video-Audio-Ausrüstung / Streaming und Datenverarbeitung konzentriert. Wir bieten alles von Beratung über Rack-Integration bis hin zu Installation, Inbetriebnahme und Schulung.
Wir bieten FM-Sender, Analog-TV-Sender, Digital-TV-Sender, UKW-UHF-Sender, Antennen, Koaxialkabel-Steckverbinder, STL, On-Air-Verarbeitung, Rundfunkprodukte für das Studio, RF-Signalüberwachung, RDS-Encoder, Audioprozessoren und Remote Site Control Units, IPTV-Produkte, Video / Audio-Encoder / -Decoder, wurden entwickelt, um die Anforderungen sowohl großer internationaler Rundfunknetze als auch kleiner privater Sender zu erfüllen.
Unsere Lösung verfügt über FM-Radiosender / Analog-TV-Sender / Digital-TV-Sender / Audio-Video-Studio-Ausrüstung / Studio-Senderverbindung / Sender-Telemetriesystem / Hotel-TV-System / IPTV-Live-Übertragung / Streaming-Live-Übertragung / Videokonferenz / CATV-Übertragungssystem.
Wir verwenden fortschrittliche Technologieprodukte für alle Systeme, da wir wissen, dass hohe Zuverlässigkeit und hohe Leistung für das System und die Lösung so wichtig sind. Gleichzeitig müssen wir auch sicherstellen, dass unser Produktsystem zu einem sehr vernünftigen Preis angeboten wird.
Wir haben Kunden von öffentlich-rechtlichen und kommerziellen Rundfunkanstalten, Telekommunikationsbetreibern und Regulierungsbehörden und bieten Lösungen und Produkte auch vielen Hunderten kleinerer, lokaler und kommunaler Rundfunkanstalten an.
FMUSER.ORG exportiert seit mehr als 15 Jahren und hat Kunden auf der ganzen Welt. Mit 13 Jahren Erfahrung auf diesem Gebiet verfügen wir über ein professionelles Team, um alle Arten von Kundenproblemen zu lösen. Wir sind bestrebt, die äußerst günstigen Preise für professionelle Produkte und Dienstleistungen zu liefern. Kontakt E-mail : [E-Mail geschützt]
UNSER WERK

Wir haben Modernisierung der Fabrik. Sie sind willkommen, unsere Fabrik zu besuchen, wenn Sie nach China kommen.

Derzeit gibt es bereits 1095 Kunden auf der ganzen Welt besuchte unser Büro Guangzhou Tianhe. Wenn Sie nach China kommen, sind Sie herzlich eingeladen, uns zu besuchen.
Am Messe

Dies ist unsere Teilnahme an 2012 Global Sources Hong Kong Electronics Fair . Kunden aus der ganzen Welt schließlich haben eine Chance, zusammen zu bekommen.
Wo ist FMUSER?
Sie können diese Nummern suchen " 23.127460034623816,113.33224654197693 "in google map finden sie dann unser fmuser büro.
FMUSER Guangzhou Büro befindet sich in Tianhe District, welche das ist Zentrum des Kantons . Sehr in der Nähe von zu den Canton Fair , guangzhou Bahnhof, Xiaobei Straße und Dashatou , brauche nur 10 Мinuten wenn übernehmen TAXI . Willkommen Freunde auf der ganzen Welt zu besuchen und zu verhandeln.
Kontakt: Sky Blue
Telefon: + 8618078869184
WhatsApp: +8618078869184
WeChat: + 8618078869184
E-Mail: [E-Mail geschützt]
QQ: 727926717
Skype: sky198710021
Adresse: No.305 Zimmer Huilan Gebäude No.273 Huanpu Straße Guangzhou China PLZ: 510620
|
|
|
|
Englisch: Wir akzeptieren alle Zahlungen wie PayPal, Kreditkarte, Western Union, Alipay, Geldbucher, T / T, LC, DP, DA, OA, Payoneer. Wenn Sie Fragen haben, kontaktieren Sie mich bitte [E-Mail geschützt] oder WhatsApp + 8618078869184
-
PayPal.  www.paypal.com www.paypal.com
Wir empfehlen Ihnen, Paypal benutzen unsere Produkte zu kaufen, die Paypal ist eine sichere Möglichkeit, im Internet zu kaufen.
Jedes unserer Artikelliste Seite unten auf ein PayPal-Logo zu bezahlen.
Kreditkarte.Wenn Sie nicht paypal haben, aber Sie Kreditkarte haben, können Sie auch den Yellow PayPal-Button klicken Sie mit Ihrer Kreditkarte zu bezahlen.
-------------------------------------------------- -------------------
Aber wenn Sie nicht über eine Kreditkarte und haben kein PayPal-Konto oder schwierig, eine paypal accout zu bekommen, können Sie verwenden, um die folgenden:
Western Union.  www.westernunion.com www.westernunion.com
Bezahlen per Western Union zu mir:
Vorname / Vorname: Yingfeng
Nachname / Nachname / Nachname: Zhang
Voller Name: Yingfeng Zhang
Land: China
Ort: Guangzhou
|
-------------------------------------------------- -------------------
T / T. Zahlung per T / T (Überweisung / Telegraphen Transfer / Banküberweisung)
Erste BANKINFORMATION (UNTERNEHMENSKONTO):
SWIFT BIC: BKCHHKHHXXX
Bankname: BANK VON CHINA (HONG KONG) LIMITED, HONGKONG
Bankadresse: BANK DES CHINA-TURMES, 1-GARTEN-STRASSE, ZENTRAL, HONGKONG
BANK-CODE: 012
Kontoname: FMUSER INTERNATIONAL GROUP LIMITED
Konto Nr. : 012-676-2-007855-0
-------------------------------------------------- -------------------
Zweite BANKDATEN (UNTERNEHMENSKONTO):
Begünstigter: Fmuser International Group Inc
Kontonummer: 44050158090900000337
Bank des Begünstigten: China Construction Bank Filiale Guangdong
SWIFT-Code: PCBCCNBJGDX
Adresse: NO.553 Tianhe Road, Guangzhou, Guangdong, Tianhe-Bezirk, China
**Hinweis: Wenn Sie Geld auf unser Bankkonto überweisen, schreiben Sie bitte nichts in das Bemerkungsfeld, da wir sonst die Zahlung aufgrund der Regierungspolitik zum internationalen Handelsgeschäft nicht erhalten können.
|
|
|
|
* Es wird in 1-2 geschickt Tage zu arbeiten, wenn die Zahlung klar.
* Wir werden es zu Ihrer paypal Adresse. Wenn Sie Adresse ändern möchten, benutzen Sie bitte Ihre korrekte Adresse und Telefonnummer per E-Mail senden [E-Mail geschützt]
* Wenn die Pakete unter 2kg ist, werden wir per Post Luftpost verschickt werden, wird es über 15-25days auf die Hand nehmen.
Wenn das Paket mehr als 2kg ist, werden wir über EMS, DHL, UPS, Fedex schnell Expressversand versendet, dauert es etwa 7 nehmen ~ 15days auf die Hand.
Wenn das Paket mehr als 100kg, werden wir über DHL oder Luftfracht schicken. Es wird etwa 3 nehmen ~ 7days auf die Hand.
Alle Pakete sind Form China Guangzhou.
* Das Paket wird als "Geschenk" verschickt und so wenig wie möglich deklariert. Der Käufer muss nicht für "STEUER" bezahlen.
* Nach dem Schiff, werden wir Ihnen eine E-Mail und geben Sie die Tracking-Nummer senden.
|
|
|
Für die Garantie.
Kontaktieren Sie uns --- >> Senden Sie den Artikel an uns zurück --- >> Empfangen und senden Sie einen weiteren Ersatz.
Name: Liu Xiaoxia
Adresse: 305Fang HuiLanGe HuangPuDaDaoXi 273Hao TianHeQu Guangzhou China.
PLZ: 510620
Telefon: +8618078869184 (XNUMX)XNUMX XNUMX XNUMX XNUMX
Bitte kehren Sie zu dieser Adresse und schreiben Sie Ihre PayPal-Adresse, Name, Problem auf Hinweis: |
|













